EXSLT set:distinct in MSXML for Internet Explorer
This article was written in 2010. Things change over time. So the information presented here may no longer be current and up-to-date, or it may have even become factually inaccurate. There may be useful information here, but you should check recent sources before relying on this article.
I’ve recently talked about how XSLT is pretty good as a presentation layer for web applications. XSLT is a powerful template language by itself but it is woefully missing several functions and interfaces which you will eventually find absolutely necessary for some purposes. EXSLT is the solution. EXSLT is a collection of extensions for the XSLT. It has numerous functions and features that XSLT is missing.
EXSLT functions are widely used and extensively tested. Not only is it available for every server-side XSLT engine, but it is also available in Mozilla Firefox, Safari, Chrome and Opera.
Unfortunately, as usual Internet Explorer throws a wrench in the whole works. Microsoft in their infinite wisdom decided not to implement the EXSLT functions and specs in their browser. Instead they implemented their own MSXSL extensions, which are frankly terrible. It doesn’t have anywhere near as much functionality as EXSLT and will never work with anything other than Internet Explorer.
The most common (and difficult to replicate) EXSLT function that I use is set:distinct. It is an extremely powerful function that lets you grab a distinct list of nodes, attributes, or values without impacting your current context in the style sheet.
This function is not available in any form in MSXML, so I decided to build it.
Building a custom function is MSXML
The MSXSL spec in MSXML does have one powerful feature that can help us rectify some of these problems, msxsl:script. This feature allows you to build script extensions inside your XSLT style sheet. Of course it only exists in the Microsoft spec, so really it’s only obvious use is spending weeks hand-crafting the standard extension functions that Microsoft decided that they didn’t need to support.
In this case I built a JScript hack to implement the set:distinct function. It isn’t nearly as powerful or flexible as the real EXSLT function, but it will grab a distinct list of nodes.
We have to use native MSXML XSLDOM scripting to do all of this and we have to return the results in the form of a NodeList so the the XSLT processor can process the output.
This is the script that I came up with:
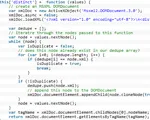
this['distinct'] = function (values) {
// create an MSXML DOMDocument
var xmlDoc = new ActiveXObject('Msxml2.DOMDocument.3.0');
xmlDoc.async = false;
xmlDoc.loadXML('<?xml version="1.0" encoding="utf-8"?>\n<distinctRoot></distinctRoot>');
var dedupe = [];
// iterate through the nodes passed to this function
var node = values.nextNode();
while (node) {
var isDuplicate = false;
// does this node already exist in our dedupe array?
for (var i=0; i<dedupe.length; i++) {
if (dedupe[i] == node.xml) {
isDuplicate = true;
break;
}
}
if (!isDuplicate) {
dedupe.push(node.xml);
// append this node to the DOMDocument
xmlDoc.documentElement.appendChild(node.cloneNode(true));
}
node = values.nextNode();
}
var tagName = xmlDoc.documentElement.childNodes[0].nodeName;
return xmlDoc.documentElement.getElementsByTagName(tagName);
}We will run this script inside a <msxsl:script language="JScript" implements-prefix="set"> statement. Notice the implements-prefix attribute, this tells the MSXML engine that this block of code will define the “set” namespace. In the code we attach a function to this['distinct'], so when we call set:distinct in the XSLT it will call this function.
This script is not perfect, and it is no where near a full implementation of the EXSLT set:distinct function. Here are the major limitations:
- Only works on NodeLists. It will not be able to return a distinct list of attributes, values, text nodes, etc. There might be a way to do those in JScript, but I couldn’t find one.
- Only one kind of node. If you want a single distinct list of
<authors>it will work, however if you want a single distinct list of<authors>and<writers>it will not work.
Important note: Do not use msxsl:script in server-side XSLTs in .NET. There have been numerous problems reported in .NET 2.0 that will case fatal memory leaks. It works fine in web browsers, just don’t use this tag in the XslTransform or XslCompiledTransform classes.
Implementing the set:distinct hack
Getting this code to work is actually quite simple once we’ve built the function. All you have to do is paste the code into the XSLT and tell the style sheet to exclude the set and msxsl prefixes. But I’ll provide a demonstration so you can see a real world working example.
First off: a sample XML file for us to show the use and purpose of the set:distinct function.
<?xml version="1.0" encoding="utf-8"?>
<?xml-stylesheet type="text/xsl" href="layout.xsl"?>
<searchresults>
<book id="21">
<title>Advanced XSLT</title>
<author id="2">Steven Benner</author>
<releasedate>February 2010</releasedate>
</book>
<book id="142">
<title>XSLT</title>
<author id="5">Doug Tidwell</author>
<releasedate>August 2001</releasedate>
</book>
<book id="15">
<title>XSLT and XPath On The Edge (Professional Mindware)</title>
<author id="3">Jeni Tennison</author>
<releasedate>July 2005</releasedate>
</book>
<book id="92">
<title>Blood, sweat and tears. The XSLT experience.</title>
<author id="2">Steven Benner</author>
<releasedate>January 2010</releasedate>
</book>
<book id="103">
<title>Beginning XSLT 2.0: From Novice to Professional (Beginning: from Novice to Professional)</title>
<author id="3">Jeni Tennison</author>
<releasedate>October 2001</releasedate>
</book>
</searchresults>I want to build a list of books grouped by author. Each author should have his or her section with their books displayed under their name.
Now we’ll create the full XSLT style sheet to implement this functionality.
<?xml version="1.0" encoding="utf-8"?>
<xsl:stylesheet version="1.0"
xmlns:xsl="http://www.w3.org/1999/XSL/Transform"
xmlns:set="http://exslt.org/sets"
xmlns:msxsl="urn:schemas-microsoft-com:xslt"
exclude-result-prefixes="set msxsl">
<!-- the msxsl script for our custom set:distinct -->
<msxsl:script language="JScript" implements-prefix="set">
<![CDATA[
this['distinct'] = function (values) {
// create an MSXML DOMDocument
var xmlDoc = new ActiveXObject('Msxml2.DOMDocument.3.0');
xmlDoc.async = false;
xmlDoc.loadXML('<?xml version="1.0" encoding="utf-8"?>\n<distinctRoot></distinctRoot>');
var dedupe = [];
// iterate through the nodes passed to this function
var node = values.nextNode();
while (node) {
var isDuplicate = false;
// does this node already exist in our dedupe array?
for (var i=0; i<dedupe.length; i++) {
if (dedupe[i] == node.xml) {
isDuplicate = true;
break;
}
}
if (!isDuplicate) {
dedupe.push(node.xml);
// append this node to the DOMDocument
xmlDoc.documentElement.appendChild(node.cloneNode(true));
}
node = values.nextNode();
}
var tagName = xmlDoc.documentElement.childNodes[0].nodeName;
return xmlDoc.documentElement.getElementsByTagName(tagName);
}
]]>
</msxsl:script>
<!-- set output mode as html -->
<xsl:output method="html"/>
<!-- this key is used to sort the results, if you don't need
to sort then you don't need a key -->
<xsl:key name="authorIds" match="author" use="@id" />
<!-- store the books in a variable because we loose
context in the foreach -->
<xsl:variable name="books" select="/searchresults/book" />
<!-- template that matches the root node -->
<xsl:template match="searchresults">
<html>
<head>
<title>Demo</title>
</head>
<body>
<h1>Results by author</h1>
<!-- for each unique author id -->
<xsl:for-each select="set:distinct(book/author)">
<!-- sort by author name -->
<xsl:sort select="key('authorIds', @id)" order="ascending" />
<!-- store the current id in a variable so we can use
it for selects -->
<xsl:variable name="authorId" select="@id" />
<h2><xsl:value-of select="key('authorIds', @id)" /></h2>
<dl>
<!-- run the book template on every book
with this author -->
<xsl:apply-templates select="$books[author/@id=$authorId]">
<!-- sort by book name -->
<xsl:sort select="title" order="ascending" />
</xsl:apply-templates>
</dl>
</xsl:for-each>
</body>
</html>
</xsl:template>
<!-- template that matches books -->
<xsl:template match="book">
<dt><xsl:value-of select="title" /></dt>
<dd>
<xsl:value-of select="author" /> / <xsl:value-of select="releasedate" />
</dd>
</xsl:template>
</xsl:stylesheet>Note the exclude-result-prefixes statement. This tells the XSLT engine that it should not render anything with these namespaces. So Firefox, Safari, Chrome, etc. will completely ignore the msxsl blocks.
This XML and XSL pair works in all modern browsers including the not-so-modern IE6.
Check out the working demo for a proof of concept.
Conclusion
As usual, Internet Explorer sucks. Microsoft’s unwillingness to adopt the same standards that every other browser lives by is hurting the internet. However, it is possible to work around some of the missing functionality. It’s just really painful and requires you to learn Microsoft specific technologies and language implementations that will never see the light of day for 60% of your users.
This particular solution is completely cross-browser compatible. Every EXSLT enabled browser will ignore the msxsl namespace and use it’s built-in set:distinct function. Internet Explorer will evaluate the script and run our custom set:distinct function.